
Produtoras e emissoras tinham arquivos espalhados em vários lugares, categorias que não faziam sentido para o próprio negócio e nenhuma forma de criar visualizações dinâmicas do conteúdo. Um sistema que armazena mas não organiza não serve ao trabalho real.
Uma emissora de TV categoriza conteúdo por data de veiculação e repórter responsável. Uma produtora corporativa categoriza por cliente e fase de aprovação. Uma produtora de entretenimento categoriza por episódio e personagem. Não existe um esquema de metadados que sirva para todos.
O affinity mapping revelou uma categoria de dor que aparecia em formas diferentes mas apontava para o mesmo lugar: organização de mídias. Alguns usuários não conseguiam encontrar o que precisavam. Outros tinham arquivos espalhados em múltiplos serviços. Outros ainda não conseguiam categorizar da forma que fazia sentido para o próprio negócio.
São reclamações diferentes com a mesma raiz: um sistema que armazena mas não organiza. Arquivos chegam, ficam disponíveis, mas não ficam encontráveis — não da forma que cada usuário precisaria.
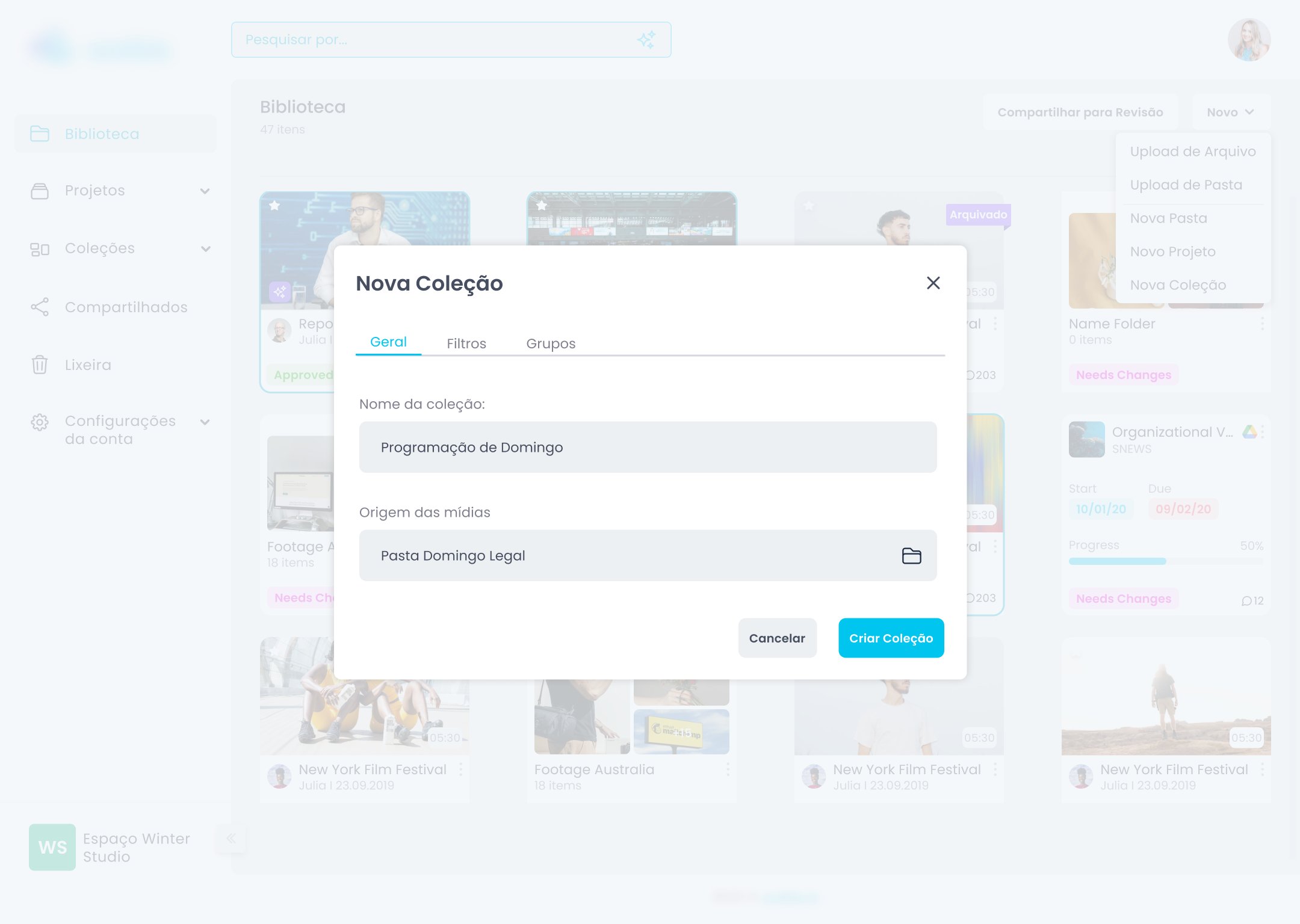
Resolvi isso em duas frentes complementares: metadados customizáveis e integração com serviços de nuvem externos.
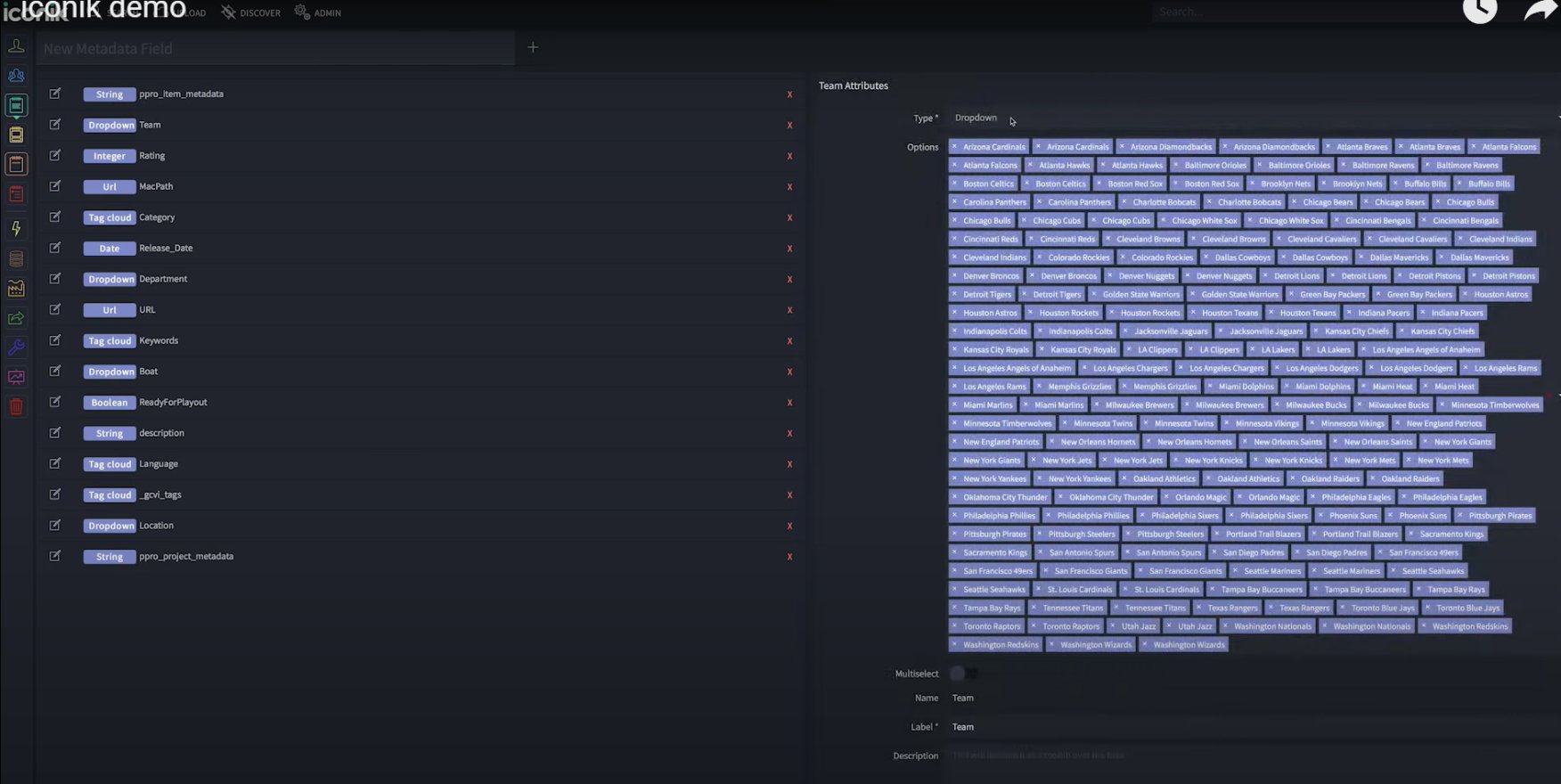
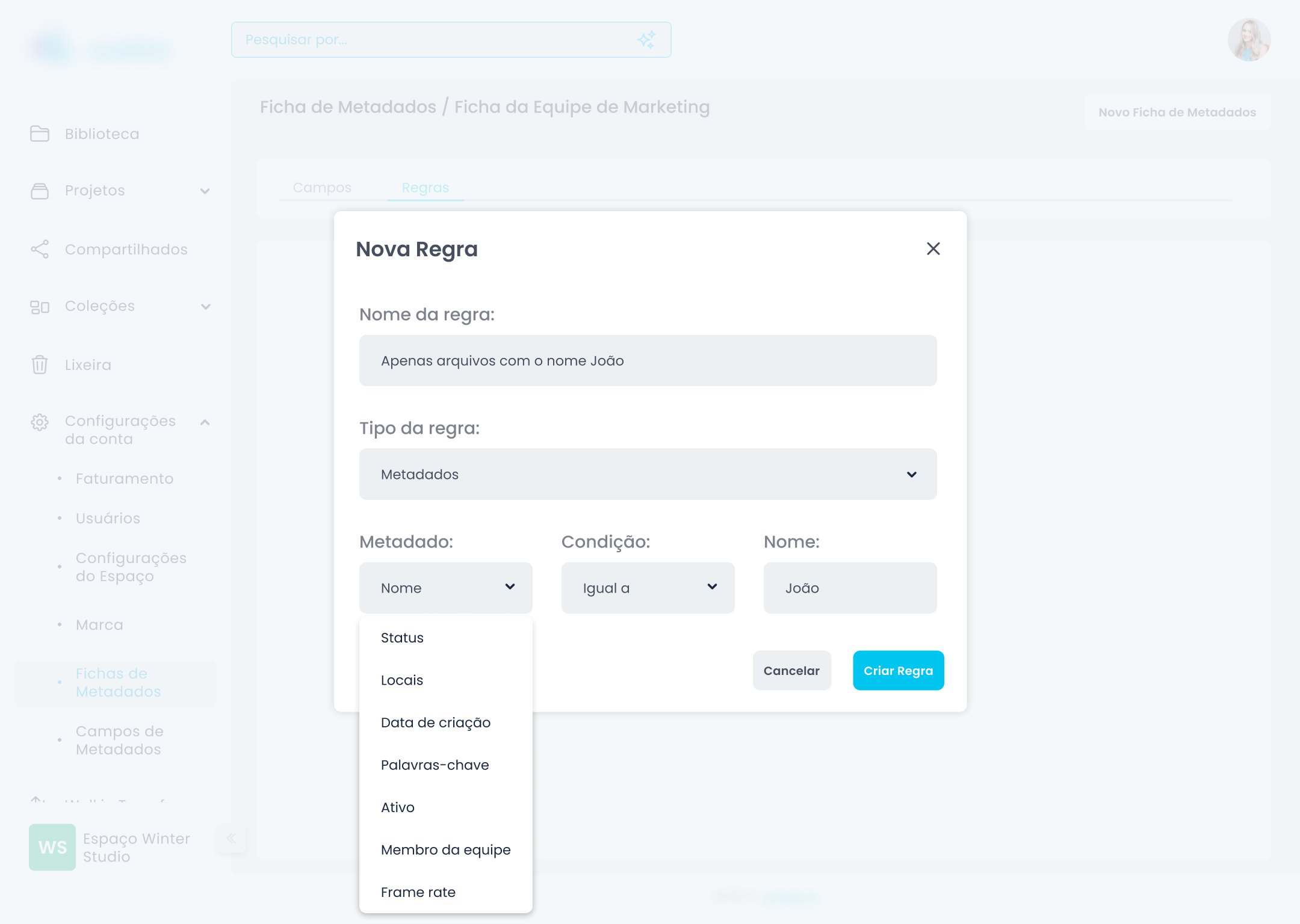
O problema com sistemas de categorização genéricos é que partem de uma premissa raramente verdadeira: que todos os usuários organizam da mesma forma. A solução foi inverter a lógica — em vez de o sistema definir como o usuário organiza, o usuário define os campos de acordo com as regras do próprio negócio.
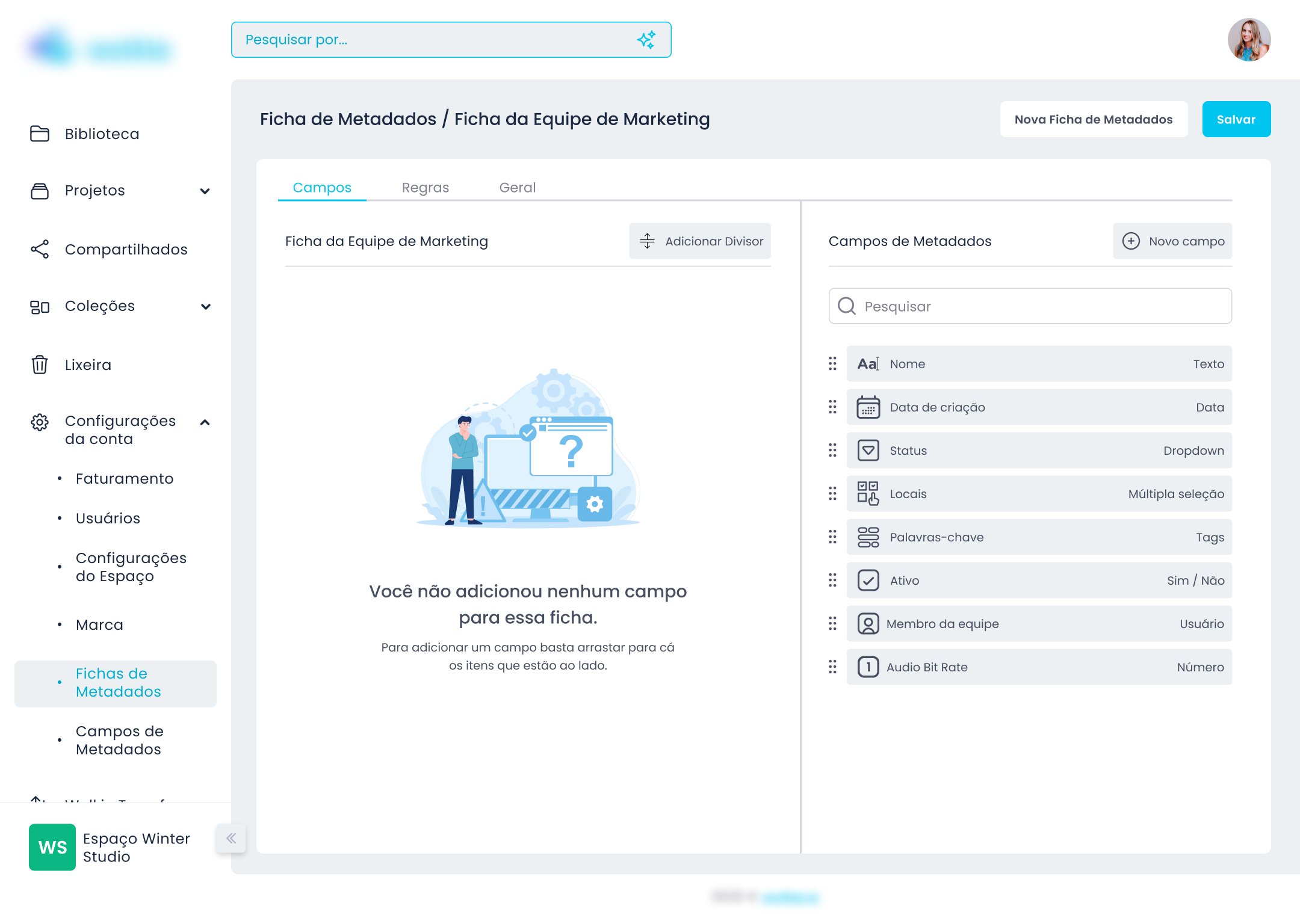
A interface de criação de fichas usa drag and drop — o usuário monta a ficha arrastando tipos de campo para a estrutura. Essa decisão veio do benchmark: sistemas como Notion e Airtable já haviam educado usuários para essa interação. Não havia razão para criar uma mecânica nova quando uma familiar já funcionava.
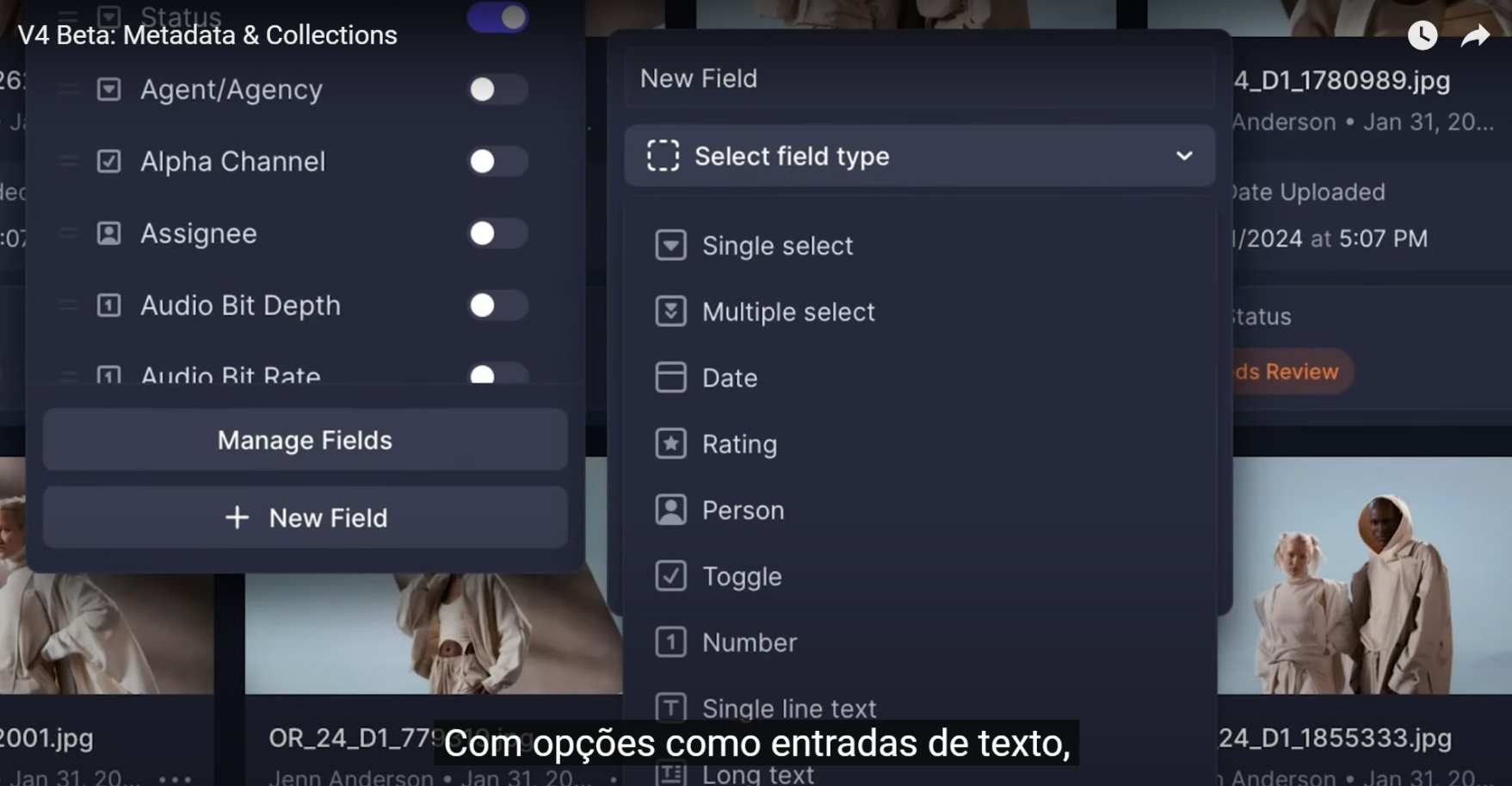
Depois de mapear a solução de metadados, identifiquei uma oportunidade que não havia aparecido nas entrevistas — mas que o benchmark deixou clara.
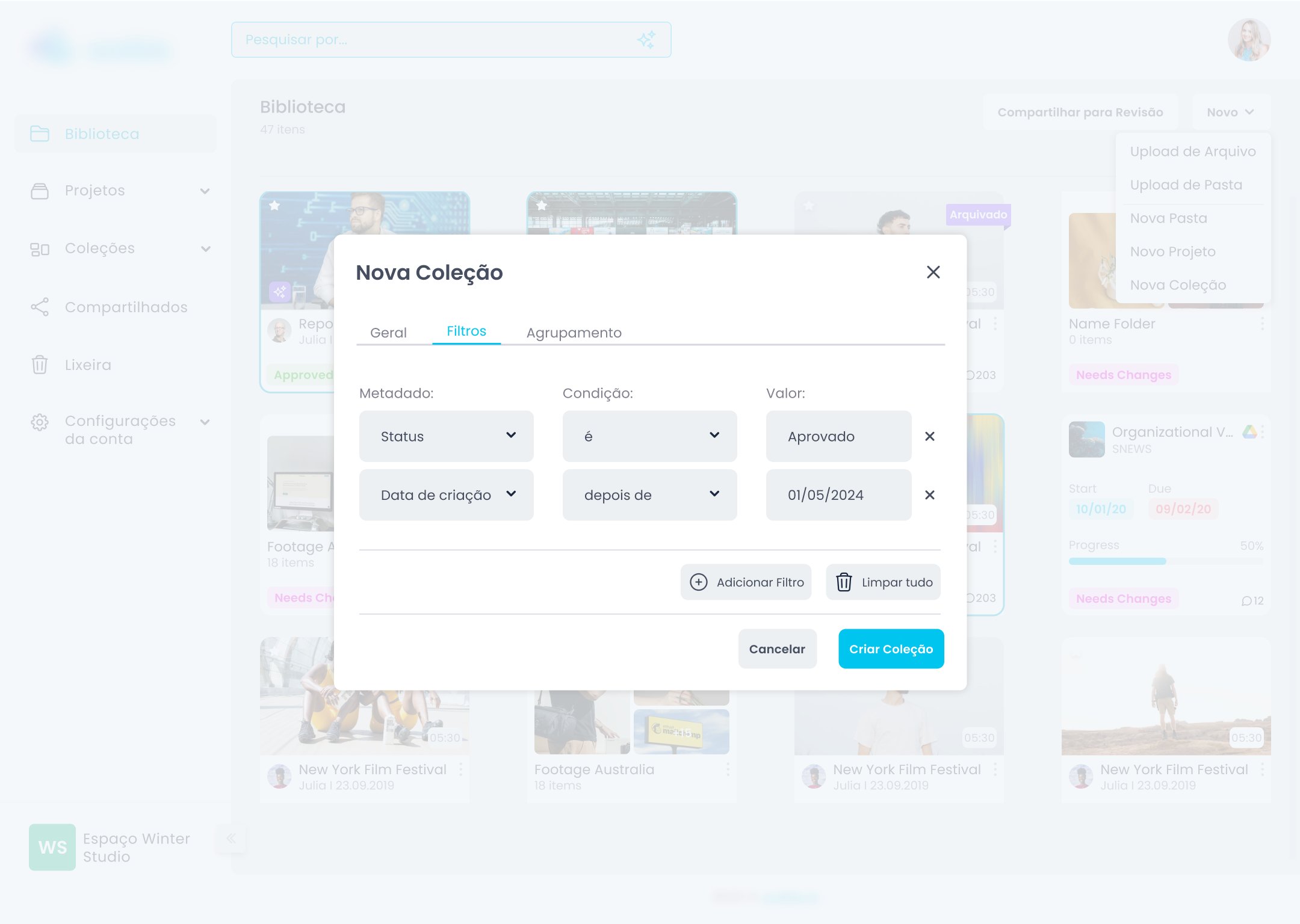
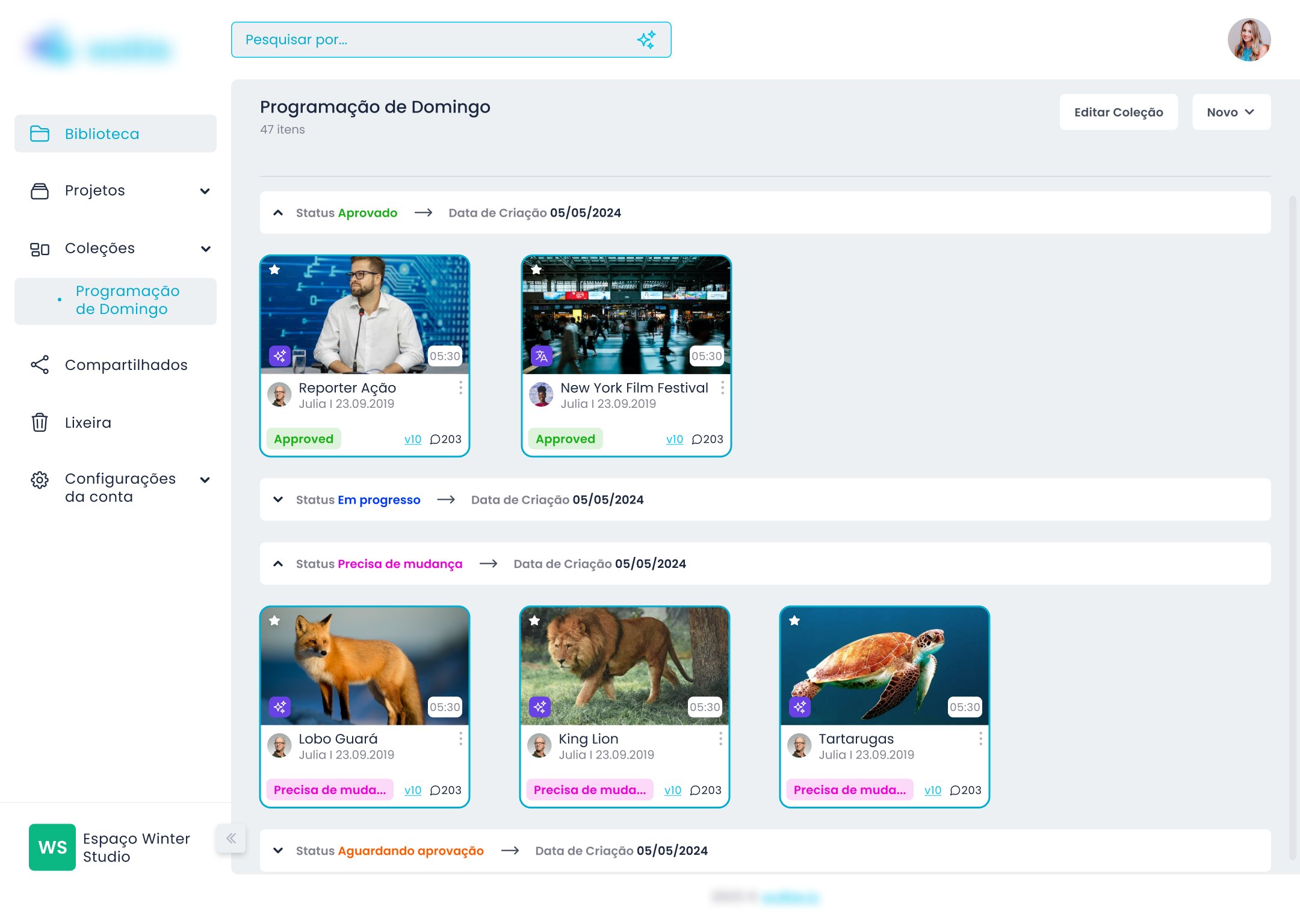
Quando o usuário tem metadados ricos, ele não quer só encontrar um arquivo. Ele quer visualizar grupos de arquivos por critério. "Todos os materiais do projeto X que ainda estão em aprovação." "Todas as entrevistas gravadas em março." "Todo o conteúdo da campanha Y que ainda não foi publicado."
A segunda frente atacou um problema diferente, mas com a mesma lógica: o usuário não deveria precisar ir a lugares diferentes para reunir o que pertence ao mesmo trabalho. Produtoras e emissoras frequentemente usam Google Drive ou Dropbox como parte do fluxo de trabalho. Substituí-los não era opção. Integrá-los era.
Conexão inicial. O usuário seleciona o serviço e escolhe quais pastas sincronizar — não a conta inteira, só o que é relevante. Pedir permissão de acesso a uma conta inteira é invasivo; pedir para selecionar pastas específicas é preciso e gera mais confiança.
Monitoramento em tempo real. Status das sincronizações visível — quais arquivos estão sendo transferidos, a velocidade, o histórico. Diferença entre integração e importação: o usuário não importa uma vez e esquece, ele tem um canal contínuo.
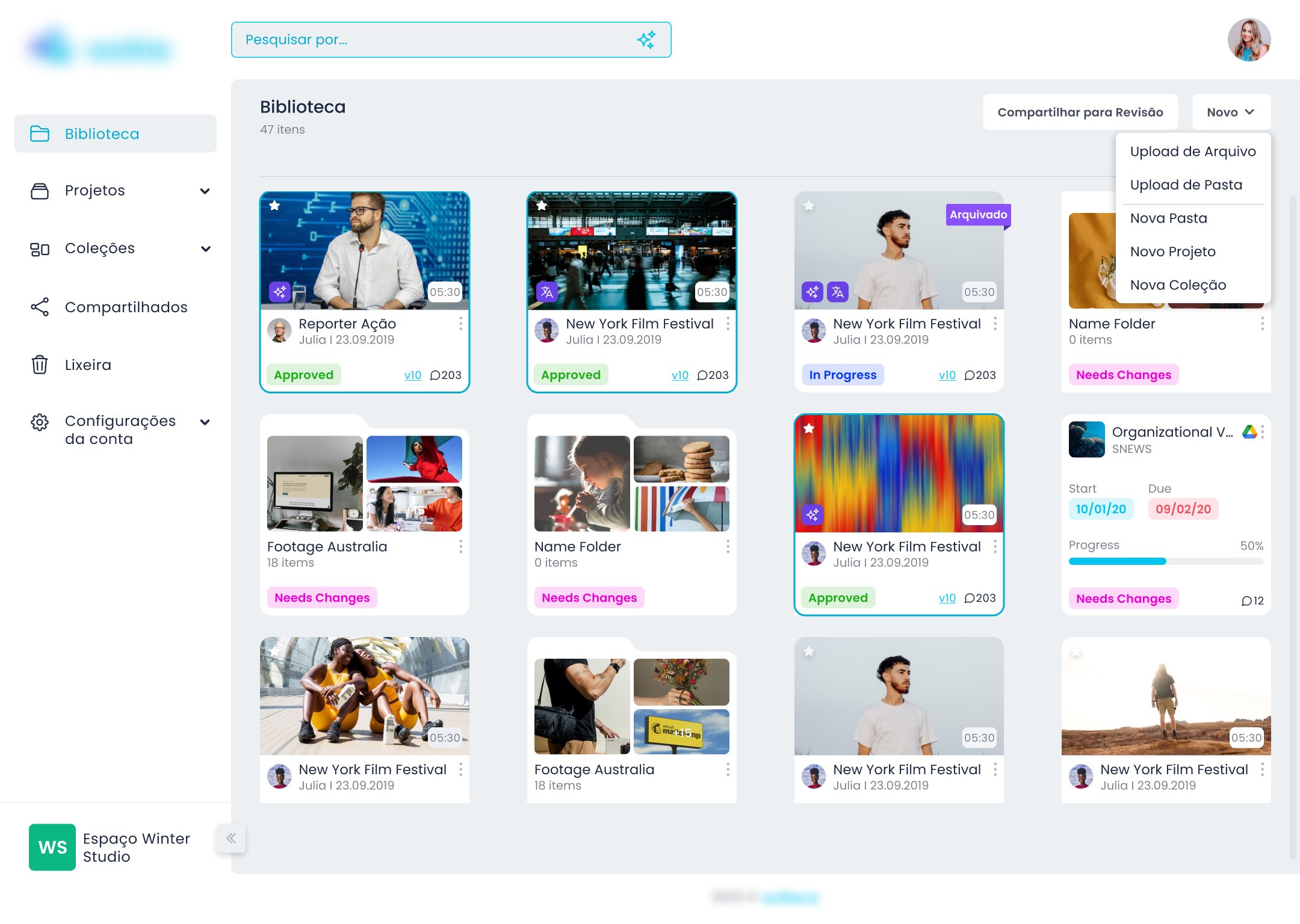
Identificação de origem. Cada arquivo que chega via integração carrega o logo do serviço de origem no card da biblioteca. O usuário sabe de onde veio cada arquivo sem precisar investigar.
As duas frentes foram implementadas. O feedback foi positivo — e de uma forma que confirmou a hipótese central: quando o sistema organiza da forma como o usuário pensa, encontrar o que se precisa deixa de ser trabalho.
"Nenhum dos dois é uma feature glamourosa. São features de infraestrutura — que não aparecem em campanha de marketing, mas são as que os usuários sentem falta quando não existem."
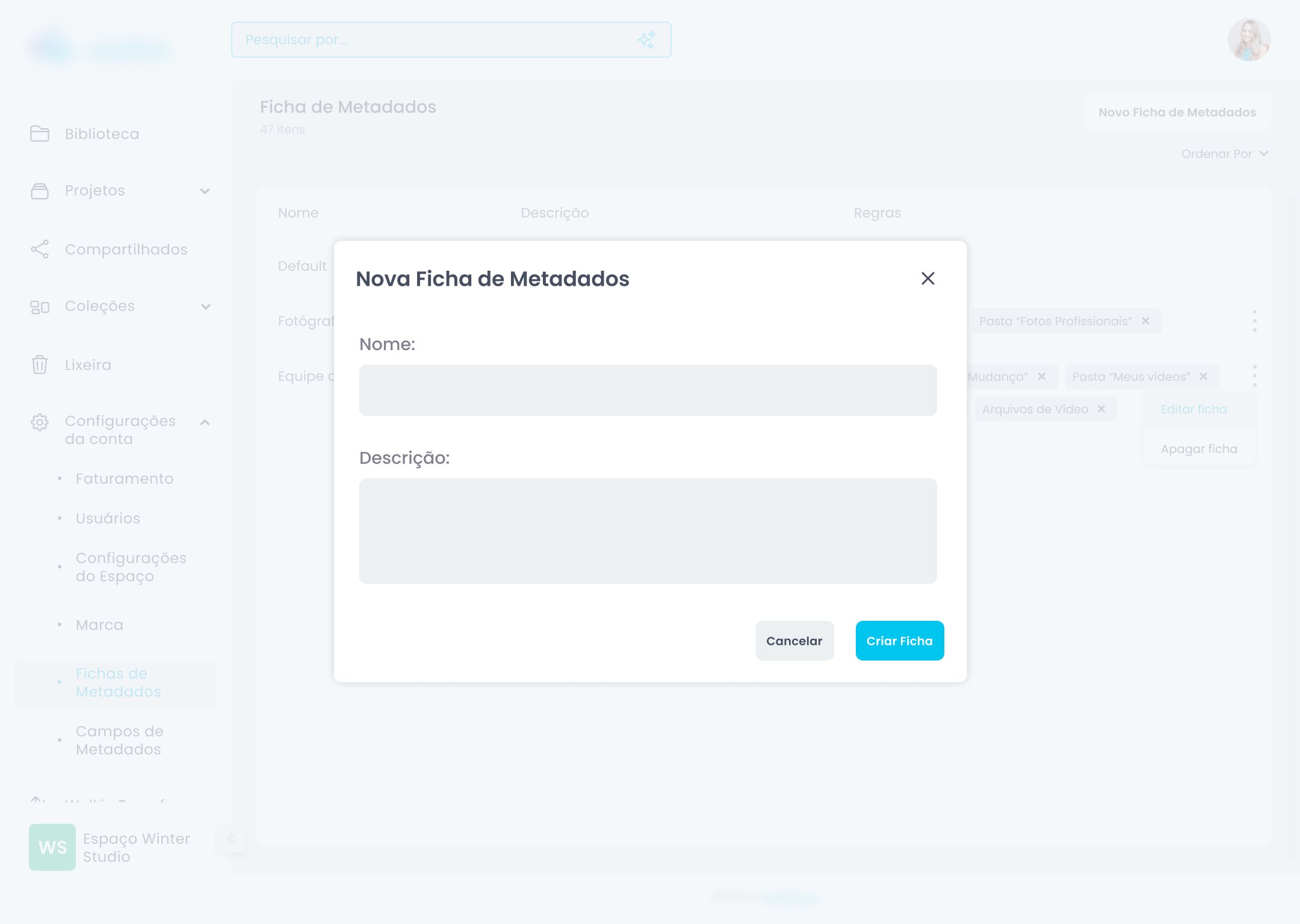
Fichas de Metadados — fluxo completo
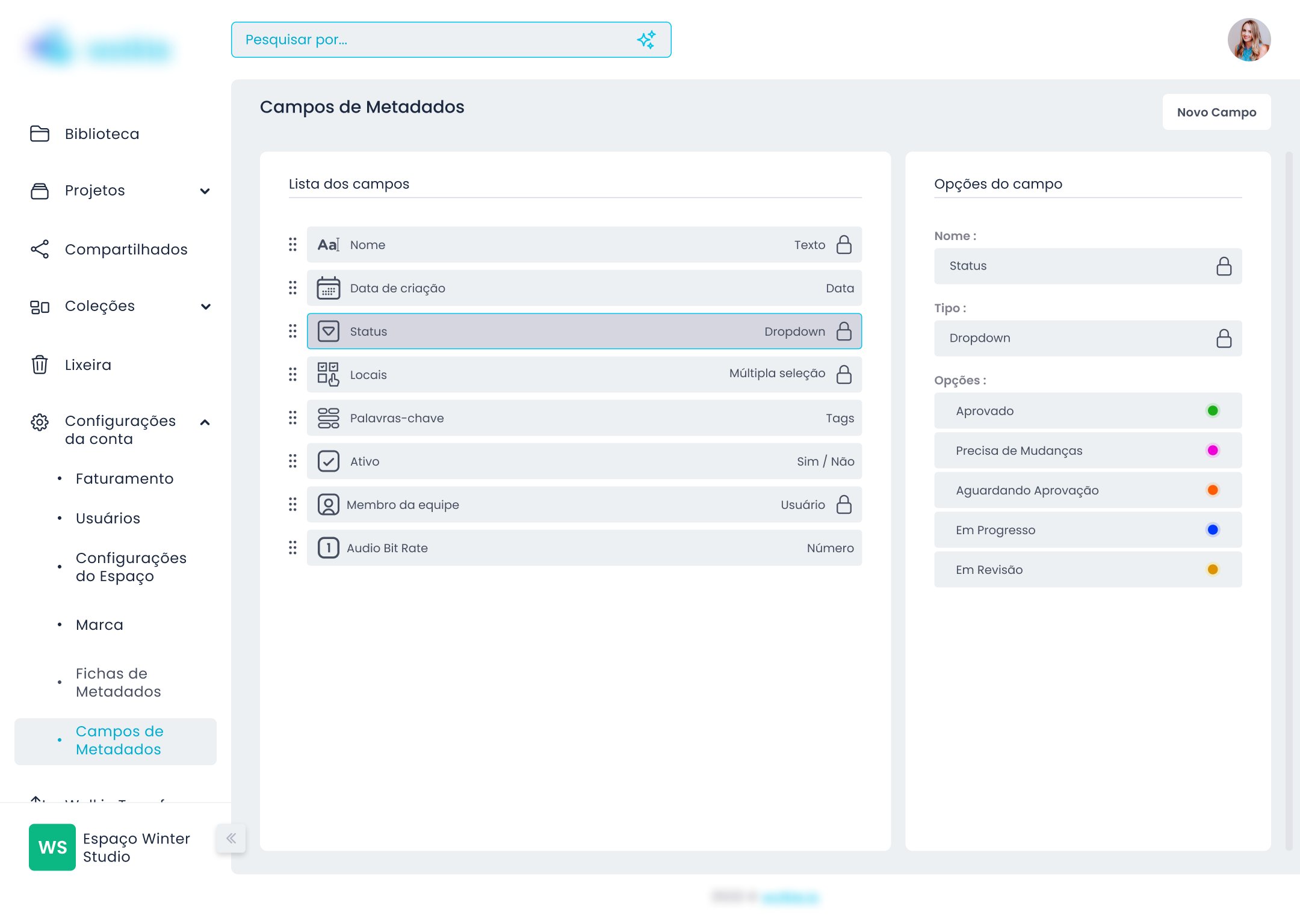
Campos de Metadados
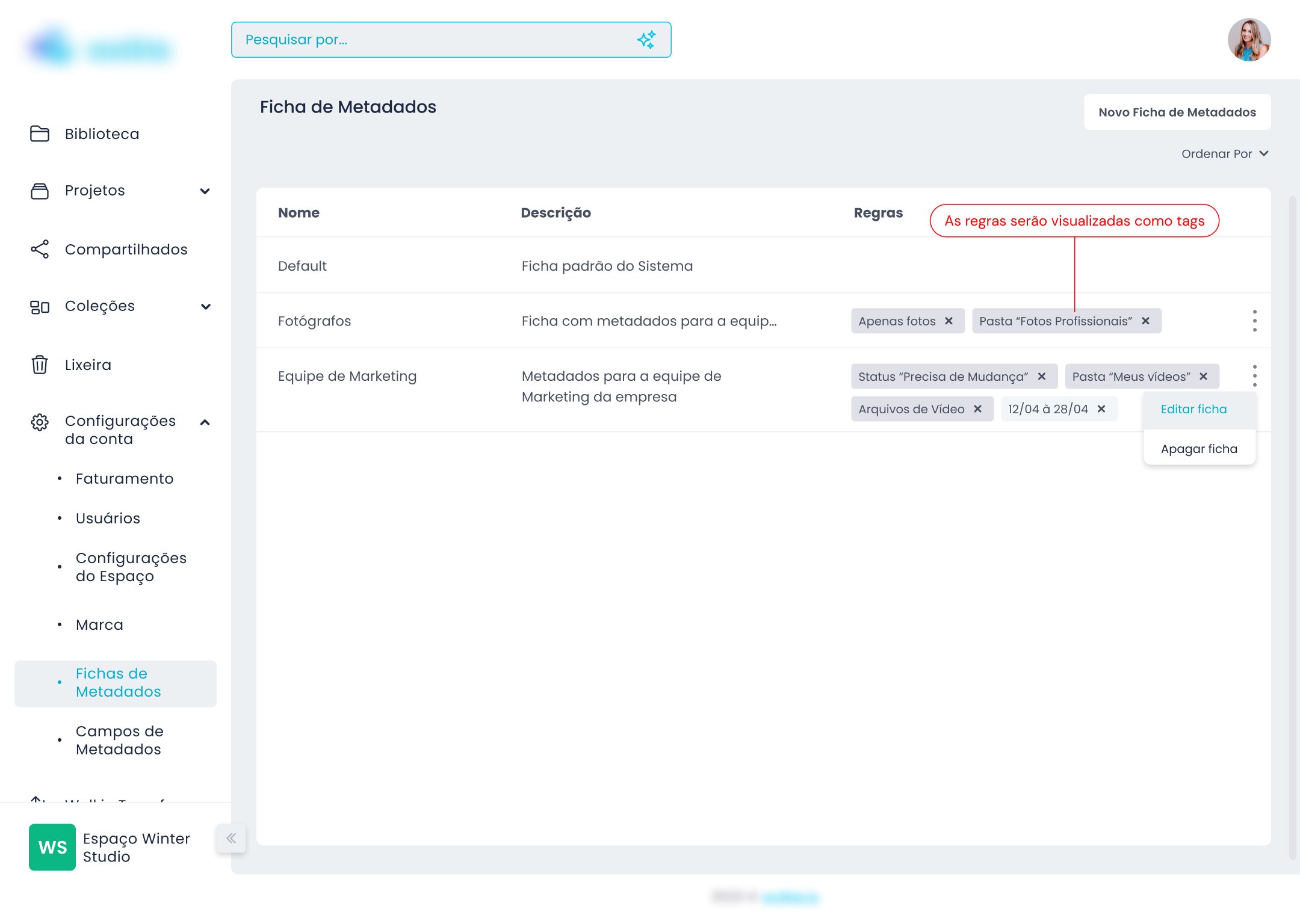
Regras de aplicação automática
Player integrado
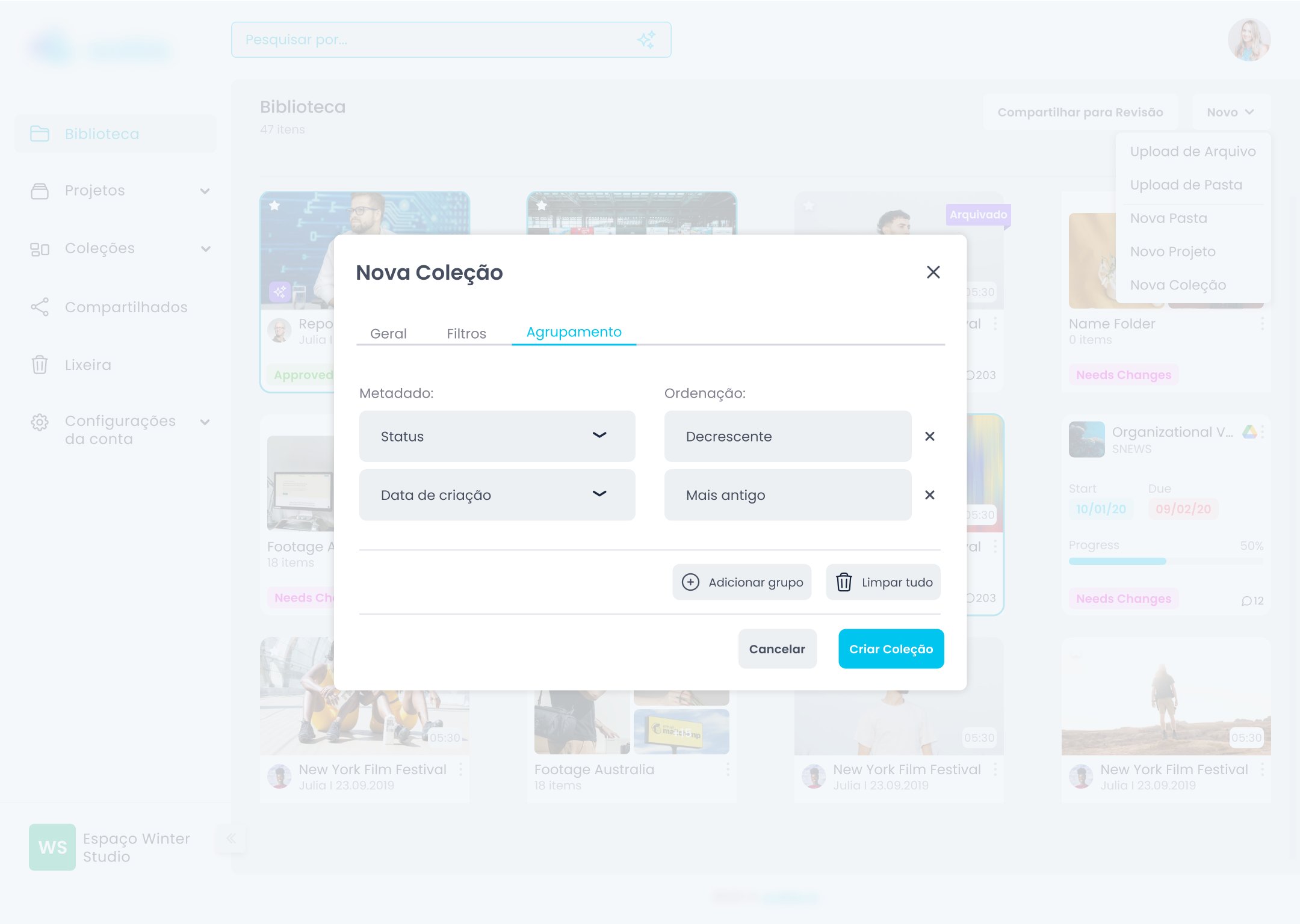
Identificar e propor as Coleções além do escopo original foi a decisão mais impactante do projeto. Transformou uma feature de categorização num sistema de trabalho ativo — e foi aceita pela liderança com base em evidência de benchmark, não em preferência de design.
As Coleções foram desenvolvidas com base em benchmark e princípio — sem validação direta com usuários da Wolkie antes do hi-fi. O que é intuitivo para quem usa Notion pode não ser para quem usa um sistema de broadcast. Alguns ajustes só apareceram depois do lançamento.
Uma rodada de testes focada especificamente na mecânica de filtros e regras das Coleções — com usuários reais da Wolkie — teria revelado ajustes que só apareceram depois do lançamento. Hipótese validada por benchmark não é o mesmo que hipótese validada pelo usuário.
A forma como uma emissora pensa em categorização é diferente da forma como uma produtora pensa. Teria conduzido entrevistas específicas sobre organização de arquivos por segmento — não apenas sobre dores gerais — para calibrar melhor os padrões de metadados propostos.